

 Michael Entner-Gómez
Michael Entner-Gómez
Why Safety Certification Assumptions Don’t Survive Reality
Blog Series: The Death of Static Safety This is the first of a six-part guest blog series titled "The Death of Static Safety". We kick things off...

This is the third part of a six-part guest blog series titled "The Death of Static Safety". Today, we dive into the following topic of avoiding a single point of failure and designing distributed safety enforcement. Let's dive in!
Part 1. Why Safety Certification Assumptions Don’t Survive Reality
Part 2. Validating Operational Assurance as a Safety Mechanism
By this point, two things should be clear. Static safety does not survive unchanged after deployment. And any mechanism that enforces behavior at runtime must be treated as a safety mechanism, not an advisory tool.
That leads to the next unavoidable question: even if operational assurance is correctly validated, does it introduce a new single point of failure?
If it does, it fails on arrival.
A common mental model of operational assurance is a centralized monitor that observes the system, evaluates risk, and intervenes when thresholds are crossed. From a software perspective, this feels clean and efficient.
From a safety perspective, it is unacceptable.
Any centralized authority that can constrain or override vehicle behavior becomes a high-criticality component. If that component fails, degrades, or behaves unexpectedly, it can compromise the entire system. Certification bodies are right to reject architectures that concentrate safety authority into a single, fragile control point.
Operational assurance cannot be bolted on as a monolith. If it is, it creates exactly the kind of systemic risk functional safety is meant to eliminate. This is critical for SOTIF. Relying on a single, centralized 'uncertainty monitor' to judge functional adequacy is itself a systemic risk. Safety must be enforced locally at the point of control.
The solution is not novel. It already exists in how safety systems are designed today.
Braking supervision is not centralized. Steering supervision is not centralized. Fault detection, arbitration, and fallback behaviors are distributed across ECUs, domains, and system layers, each operating within defined responsibilities and failure assumptions.
Operational assurance must follow the same pattern.
Rather than acting as a global authority, assurance enforcement must be decomposed and allocated. Constraints belong where they can be enforced safely and predictably. Some checks are local.
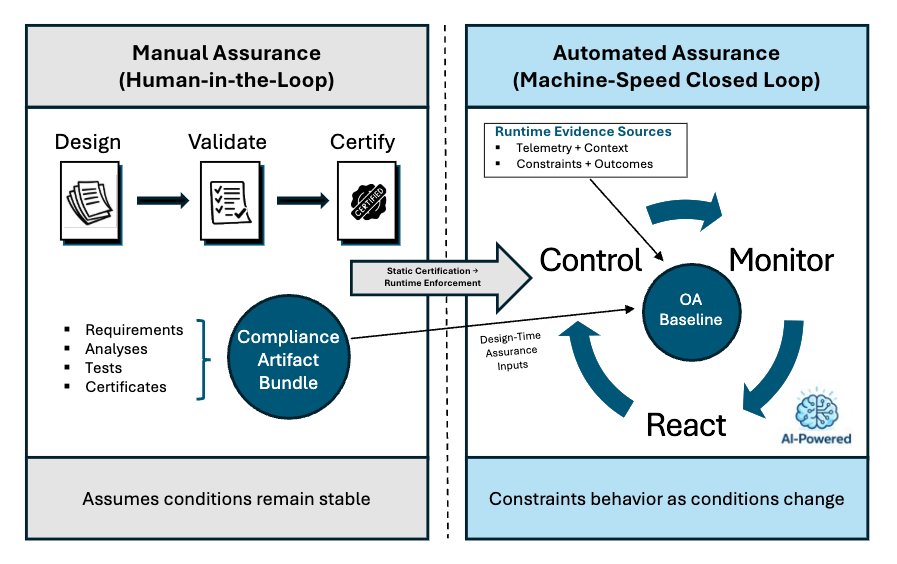
The OAS architectural model, showing the distributed relationship
between the System, Control, and Monitor layers.
Some are domain-level. Some are system-level. No single element is responsible for “overall safety.”
This is not about redundancy for redundancy’s sake. It is about preserving fault containment and predictable failure modes.
A centralized monitor often fails another safety expectation: meaningful fail-safe behavior.
If assurance degrades, times out, or loses confidence, the system must transition safely. That transition cannot be improvised. It must be a pre-certified operational state that has been analyzed for secondary hazards.
Simply disabling autonomy or transitioning to a Minimal Risk Condition (MRC) due to an ODD boundary violation must be as deterministic as a hardware fault response. In some contexts, it can introduce new hazards. Safety supervision must therefore include context-aware transitions, not blanket shutdown logic.
Distributed enforcement enables this. Local supervisors can respond appropriately to local conditions without waiting for a global authority to decide.
Operational assurance does not get a pass on classic safety principles.
Any enforcement element that carries ASIL-relevant authority must meet expectations for independence, fault detection, and fault containment. Assurance logic cannot quietly become a backdoor for coupling unrelated subsystems.
If one enforcement element fails silently, others must continue to operate. If communication is degraded, safe behavior must still emerge. These are the same expectations placed on existing safety supervisors, and operational assurance must meet them without exception.
Designing assurance as distributed supervision is not just an architectural preference. It is a certification requirement.
At this point, the debate about whether operational assurance is “safe” largely disappears. The real question becomes architectural.
A centralized assurance system is fragile by definition. A distributed enforcement architecture inherits the industry-accepted fault tolerance and certification logic.
This is why operational assurance must be designed as a safety mechanism from the beginning. Retrofitting safety expectations onto a centralized analytics platform does not work. Decomposing assurance into verifiable, bounded, and independently supervised elements does.
Validation answers the question of whether assurance can belong in the safety chain. Architecture determines whether it deserves to.
A correctly validated assurance mechanism that introduces a new single point of failure is still unacceptable. Only a distributed, fail-safe supervision model allows operational assurance to extend safety without undermining it.
In the next article, the focus shifts again. Even a distributed assurance system can fail to meet certification expectations if it violates the freedom from interference. The question then becomes how runtime enforcement can coexist with mixed-criticality systems without breaking ASIL partitioning.
LHP Operational Assurance Systems (OAS) was spun out of LHP Engineering Solutions to address a growing gap in safety-critical, software-defined systems: certification at launch no longer guarantees safe operation over time. As complex platforms began receiving continuous software updates and evolving functionality, LHP OAS recognized that traditional "certify-once" models could not prevent runtime drift between validated safety intent and real-world behavior. Drawing on decades of leadership in functional safety, cybersecurity, and systems engineering, LHP OAS was formed to focus exclusively on extending certified intent into live environments and developed a platform, Operational Assurance Sentinel, that embodies this concept. LHP's Operational Assurance Sentinel platform delivers deterministic runtime enforcement, operational assurance scoring, and tamper-evident evidence chains that transform safety from a static milestone into a continuously verifiable discipline, enabling organizations to deploy advanced autonomous and intelligent systems with measurable, provable confidence.

Blog Series: The Death of Static Safety This is the first of a six-part guest blog series titled "The Death of Static Safety". We kick things off...

Blog Series: The Death of Static Safety This is the second part of a six-part guest blog series titled "The Death of Static Safety". Today, we dive...

Construction's Software-Defined Moment This blog was originally posted by Michael Entner-Gómez on his Substack on 2/13/26.
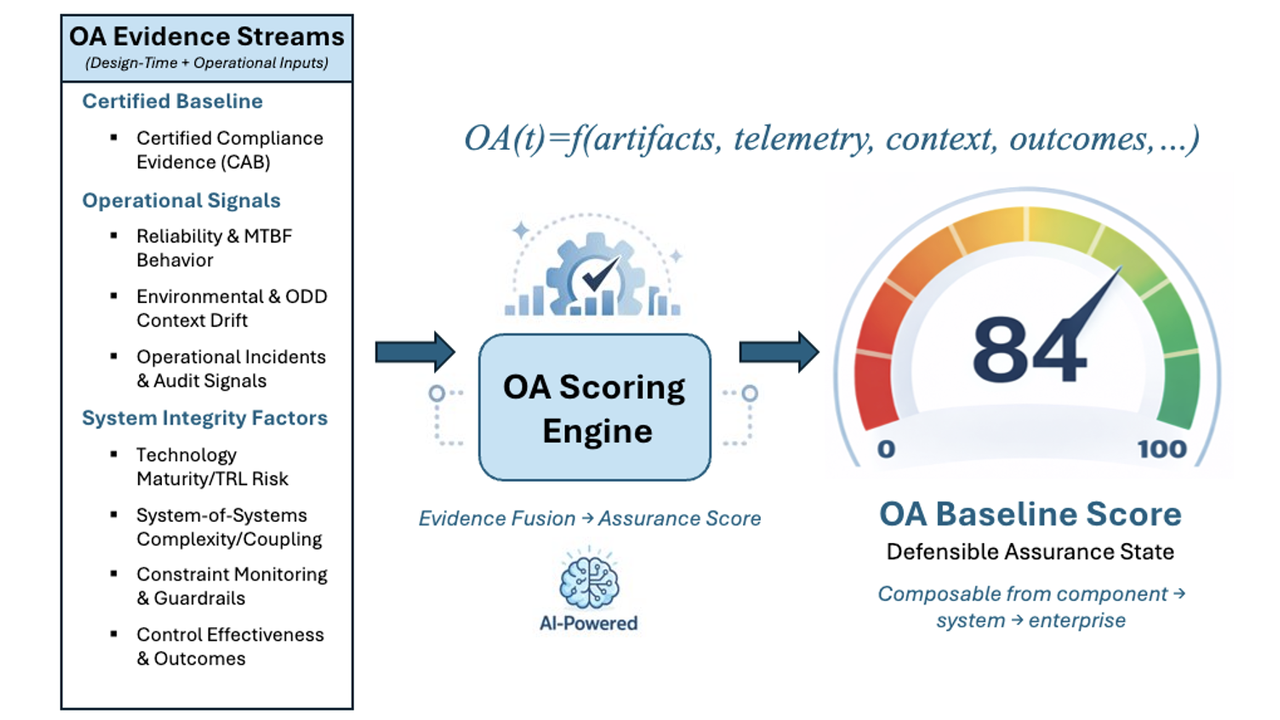
Blog Series: The Death of Static Safety This is the fifth part of a six-part guest blog series titled "The Death of Static Safety". For today's post,...
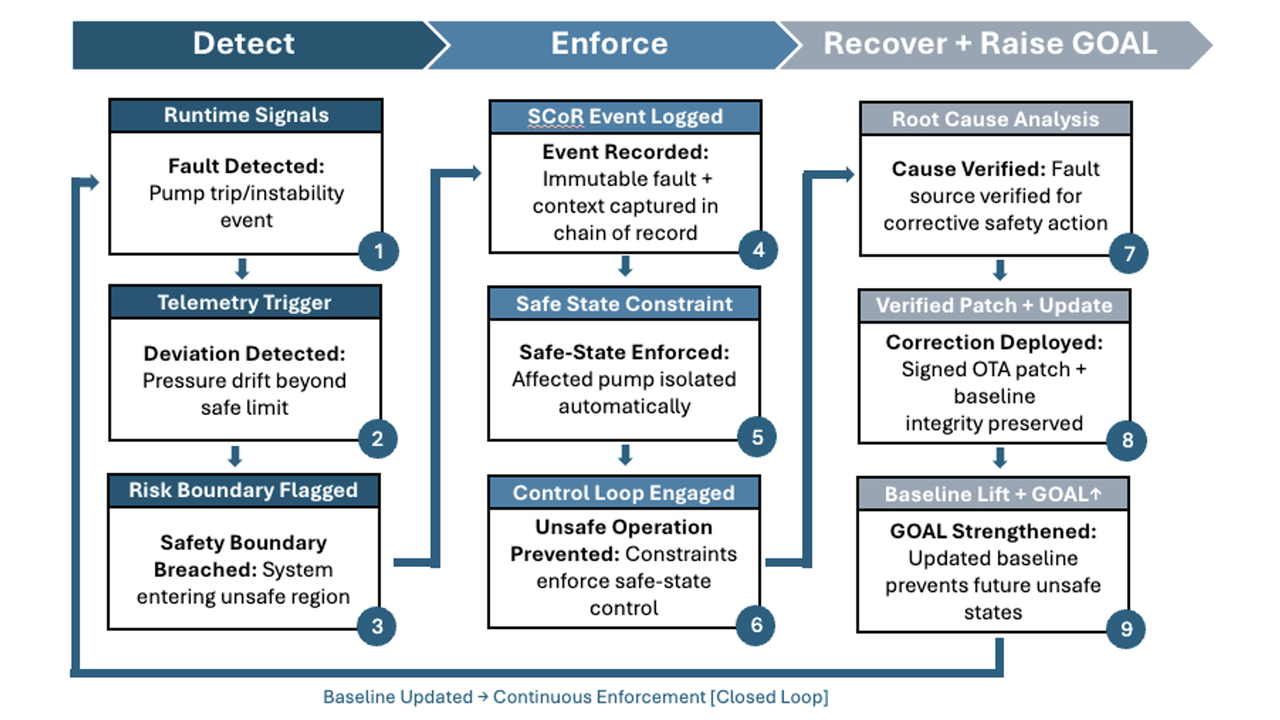
Blog Series: The Death of Static Safety This is the fourth part of a six-part guest blog series titled "The Death of Static Safety". For today's...

Blog Series: The Death of Static Safety This is the sixth and final part of a guest blog series titled "The Death of Static Safety". Today, we wrap...